はじめに
こんにちは!ウィルゲート開発グループの中尾(@NobleNomad41)です!
今回は、運営7年目を迎えた弊社プロダクトのファイルアップロード機能を改善した取り組みについて書いてみたいと思います。
結果からお伝えすると、3GBのファイルアップロードが5分から1分13秒になりました。約4倍の改善です!
ただし、今回の改修で一番面白かったのは、実はパフォーマンス改善の手法だけではありません。当プロダクトのコア機能をどうやって安全に移行したのかという点も併せてご紹介します。
長期運営による技術負債、既存コードへの影響範囲の不透明さ、そしてビジネスへの致命的な影響リスク。これらをDDD(Domain Driven Design)の設計原則と丁寧なテスト戦略で乗り越えながら、同時にパフォーマンス改善を実現する必要がありました。
この「技術選択」と「安全な移行戦略」の両立が、今回本当に学びの多い部分でした。どうやって4倍の改善を実現したのか、そしてそれを安全に本番環境に適用したのかを、できるだけ具体的にお話ししていこうと思います。
ちなみに僕は可読性とパフォーマンスの両立が大好きな設計オタクなので、その辺りの葛藤もリアルに書いていきます。DDDも大好きなので、今回はそっち方面でも色々試せて楽しかったです!
改修前の課題
今回改修を行った弊社のプロダクトは、クライアントとクリエイターのアサインや案件のやり取り、そして最終的なファイル納品を軸としたBtoBサービスです。制作会社やフリーランスのクリエイターが、動画制作や各種コンテンツ制作の完成ファイルをクライアントに納品するという流れの中核を担っています。
そのため、ファイルアップロード機能はまさにコア機能です。10MBの軽いファイルから3GBを超える大容量ファイルまで、本当に多様なファイルを日常的に扱います。
7年運営による技術負債の蓄積
運営7年目を迎えたプロダクトには、正直なところ、様々な技術負債が蓄積されていました。
まずアーキテクチャが複雑化してたんです。機能追加の積み重ねで、ファイルアップロード周りの処理が複数箇所に散在している状態でした。
それから、テストカバレッジに課題がありました。プロダクト全体で単体テスト・統合テストが手薄で、ファイルアップロード機能についても改善の余地がある状況でした。
ほか、守られていないアーキテクチャも問題でした。人の入れ替わりも激しかった結果、アーキテクチャが守られておらず、負債コードの上にコードを継ぎ足すような状態になってました。当然、変更時にどこまで影響が及ぶか予測することが困難でした。
従来システムの具体的な問題
フロー自体が「ユーザのブラウザ → サーバー → S3」という形で、EC2インスタンスを必ず経由する設計になってました。

これの何が問題かというと、まずアップロード時間が長いということなんです。3GBのファイルで5分かかってしまう。パフォーマンス好きの僕からすると「いやいや、これはちょっと...」って感じでした。
それから、アップロード中はEC2のCPU使用率が跳ね上がって、他の処理にも影響が出る。実際、エラーログを見ると既知エラーの大部分がファイルアップロード・ダウンロード関連でした。
特に困ったのが、4GBを超えるファイルへの対応です。技術的には可能でしたが、サーバー負荷とアップロード時間を考慮すると現実的じゃありませんでした。結果として、大きなファイルは外部のファイル転送サービスを使ってもらうという、プロダクトとしては本末転倒な運用になってました。
そこで今回、アップロード改善のためS3のマルチパートアップロード機能が候補に上がりました。
技術選択の検証プロセス
改修を始める前に、不確実性を潰す意図も含め、本当にマルチパートアップロードで効果があるのかを徹底的に検証しました。机上の理論だけで進めて後から「思ったより改善しなかった」となるのは避けたかったので。これは結果的に良かったなと思います。
まず動かしてから考える派の僕としては、とりあえず試してみることにしました!
検証環境設定
検証条件をこんな感じで統一しました。
- ファイルサイズ 3GB
- チャンクサイズ 50MB
- リージョン ap-northeast-1(東京)
チャンクサイズを50MBに設定した理由は、AWS の推奨値やネットワーク環境を考慮した結果です。小さすぎるとリクエスト数が増えてオーバーヘッドが大きくなり、大きすぎると1つのチャンクの転送失敗時のロスが大きくなります。
実際には10MB、25MB、50MBで比較検証を行い、50MBが一番効率的でした。実際に手を動かしてみないと分からないものですね。
検証結果比較
4つのアプローチで検証を行いました。結果をまとめてみると、かなり興味深い傾向が見えてきました。
| アップロード方式 | 速度 | 料金/回 | API負荷 | クライアントPC負荷 | 備考 |
|---|---|---|---|---|---|
| 従来 (フロント→API→S3) |
5:00 | 0.05円 | 62回・重い | 低 | 遅い、API負荷高い |
| マルチパートなし (フロント→S3直接) |
1:30 | 0.0016円 | 2回 | 低 | シンプル・安価だが復旧性に課題 |
| 並列なしマルチパート | 2:17 | 0.05円 | 62回 | 低 | CPU使用率1/3に改善、API負荷高い |
| 並列ありマルチパート (最大5個並列) |
1:13 | 0.05円 | 3回 | 高 | 一番速い、PCスペック依存 |
この数字見てください!並列ありマルチパートが圧倒的やん🔥
やはり数字。数字はすべてを解決する。
並列ありマルチパートアップロードの採用理由
並列ありマルチパートアップロードを採用した理由は、もちろんアップロード速度が一番速かったことです。
でも、副次的ではありますが並列ありマルチパートアップロードでEC2側のAPI負荷が劇的に改善したことも採用理由の一つです。「なるほど!これはリクエスト数削減だから確かに刺さるな」って感じです。
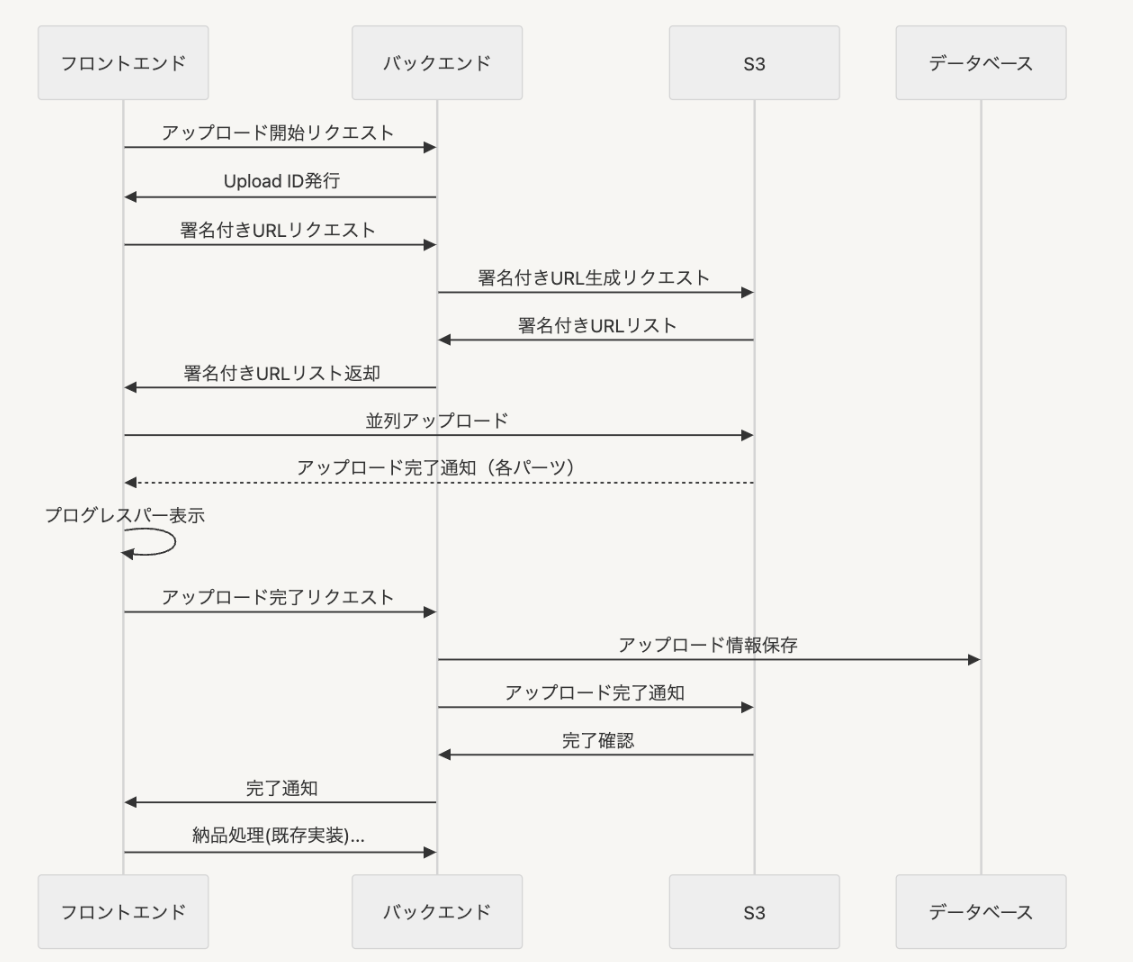
もともとチャンクアップロードというファイル分割を行い分割した回数分だけAPIを叩いてアップロードしてたんですが、並列ありマルチパートアップロードにすることでファイルサイズに関係せず3回だけしかAPIを叩かなくなりました。
- 開始リクエスト 1回
- 署名付きURL一括取得 1回
- 完了リクエスト 1回
結果、APIを展開しているEC2のCPU使用率を従来の約3分の1まで下げることができました。やはりパフォーマンス改善って最高ですね。
最終的に、並列ありマルチパートアップロード(5個まで並列)で1分13秒という結果を得ることができました。
料金面での検討
性能だけでなく、料金面での影響も検討しました。パフォーマンスと運用コストのバランスは悩ましいところですね...
前提条件
まず前提条件を整理してみます。
- ファイルサイズ 3GB(3,072MB)
- チャンクサイズ 50MB
- リージョン ap-northeast-1(東京)
- リクエスト料金 PUT、COPY、POST、LIST が 1,000リクエストあたり $0.005
料金計算の詳細
それぞれの方式での料金計算はこんな感じになりました。
マルチパートなしS3アップロード
リクエスト回数: 2回 料金: 2 × $0.005 × 0.001 = $0.000010 (0.0016円)
マルチパートありS3アップロード
チャンク数: 3,072MB ÷ 50MB = 61.44 → 62個 開始・終了リクエスト: 2回 合計リクエスト回数: 64回 料金: 64 × $0.005 × 0.001 = $0.00032 (0.05円)
料金比較結果
実際の料金を比較してみると、こんな感じでした。
| アップロード方式 | リクエスト回数 | 料金/回 | 倍率 |
|---|---|---|---|
| マルチパートなし | 2回 | 0.0016円 | 1倍 |
| マルチパートあり | 64回 | 0.05円 | 31倍 |
確かに料金だけ見ると31倍の差があるんですが、絶対値では一回あたり0.05円程度の差でしかありません。得られるパフォーマンス向上(約4倍)と復旧性を考慮すると、十分に許容できる範囲だと判断しました。
コストよりもユーザー体験重視で行きました!
DDD設計での実装アプローチ
今回の改修では、Domain Driven Designの考え方(あくまで設計論のみ。戦術DDDや軽量DDDと呼ばれている方)を積極的に取り入れました。DDD大好きな僕としては、これはもう絶対にやりたかった部分です!✨
といっても、理論的な美しさを追求するためではなく、実用的な理由からです。理論ではDDDの恩恵はわかってはいたのですが実際にやってみるとその価値がよくわかりました。
アーキテクチャの変更
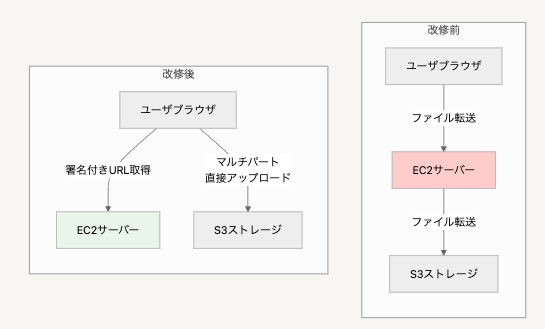
ドメイン中心設計による価値の創出
今回の設計で一番重要だったのは、ファイルアップロードに関するビジネスルールをDomainレイヤーに集約したことでした。
従来のコードでは、ファイルアップロードの複雑なビジネスルール(サイズ制限、拡張子チェック、進捗管理、リトライロジックなど)が、フロントエンド、バックエンド、さらには設定ファイルにまで散在してました。これが本当に厄介で、どこに何があるのかわからない状態だったんです。
ドメインモデルによる知識の集約を行いました。これはもう美しい設計としか言いようがない。
<?php class FileUpload { private FileName $fileName; private FileSize $fileSize; private UploadProgress $progress; public function validateForUpload(): ValidationResult { // ファイルアップロードのビジネスルールを集約 if (!$this->fileName->hasValidExtension()) { return ValidationResult::invalid('不正な拡張子です'); } if ($this->fileSize->exceedsLimit(FileSizeLimit::forMultipart())) { return ValidationResult::invalid('ファイルサイズが上限を超えています'); } return ValidationResult::valid(); } public function calculateOptimalChunkSize(): ChunkSize { // ファイルサイズに応じた最適なチャンクサイズを計算 return $this->fileSize->calculateOptimalChunkSize(); } }
これにより、「どこに何のロジックがあるか」が明確になり、ビジネスルールの変更時にも影響範囲を限定できるようになりました。実際、他のアップロード機能でも同じドメインモデルを再利用でき、開発効率が向上しました。
可読性とパフォーマンスの両立、最高です!
揮発性依存のDIによる柔軟な設計
S3というAWSサービスへの依存は、本来「ファイルを保存する」というドメインの関心事とは無関係な技術的詳細です。このような揮発性の高い外部依存をDependency Injectionで抽象化することで、ドメインロジックを純粋に保つことができました。
<?php interface ExternalStorageInterface { public function generateUploadUrls(UploadSession $session): UploadUrls; public function completeUpload(UploadSession $session): StorageLocation; public function deleteIncompleteUpload(UploadSession $session): void; } class S3Storage implements ExternalStorageInterface { // S3固有の実装詳細 public function generateUploadUrls(UploadSession $session): UploadUrls { // S3のマルチパートアップロード固有の処理 } } class UploadService { public function __construct( private ExternalStorageInterface $storage ) {} public function executeUpload(FileUpload $fileUpload): UploadResult { // ドメインロジックのみに集中、ストレージの詳細は気にしない $validation = $fileUpload->validateForUpload(); if (!$validation->isValid()) { return UploadResult::failed($validation->getMessage()); } $session = UploadSession::create($fileUpload); $urls = $this->storage->generateUploadUrls($session); return UploadResult::started($urls); } }
この設計により、将来的にS3から別のクラウドストレージに変更することになっても、ドメインロジックには一切手を加える必要がありません。また、テスト時にはモックストレージを注入することで、外部サービスに依存しない高速なテストが実現できました。
Package by Featureの採用
ファイルアップロード機能を独立した境界づけられたコンテキストとして設計することで、既存のコードへの影響を抑えられると考えました。
src/ ├── upload/ # アップロード境界コンテキスト │ ├── domain/ # ドメインロジック(FileUpload, UploadSession等) │ │ ├── models/ │ │ ├── services/ │ │ └── repositories/ │ ├── application/ # アプリケーションサービス(UploadService等) │ ├── infrastructure/ # インフラストラクチャ(S3Storage等) │ └── presentation/ # プレゼンテーション層 ├── legacy-upload/ # 従来の実装(移行期間中) └── ...
腐敗防止層による安全な移行
境界づけられたコンテキストと関連しますが、既存システムとの統合時には既存箇所を腐敗防止層(Anti-Corruption Layer)でWrapし、ファイルアップロード機能のコンテキストを崩さないようにしました。
テスト戦略の重要性
単体テストを網羅的に実装することで、各コンポーネントの独立性を保ちながらテストできました。
特にDomainレイヤーのテストを充実させたことで、ビジネスロジックの正確性を保証し、機能結合時も差し戻しが発生することなく動作確認できました。これは7年運営で技術負債が蓄積したプロダクトにおいて、本当に重要な安全装置となりました。
実際に手を動かしてテストを書いてみると、設計の穴が見えてくるのも気づきですね。
マルチパートアップロードの実装詳細
フロントエンド実装
フロントエンド側では、次のような流れでマルチパートアップロードを実装しました。
フロントエンド大好きな僕としては、このあたりの実装は楽しかったです!
class MultipartUploader { constructor(file, options = {}) { this.file = file; this.chunkSize = options.chunkSize || 50 * 1024 * 1024; // 50MB this.maxConcurrency = options.maxConcurrency || 5; this.apiBaseUrl = options.apiBaseUrl; } async upload() { try { // Step 1: マルチパートアップロード開始 const uploadId = await this.startMultipartUpload(); // Step 2: 署名付きURL一括取得 const presignedUrls = await this.getPresignedUrls(uploadId); // Step 3: 並列アップロード実行 const parts = await this.uploadParts(presignedUrls); // Step 4: アップロード完了 const result = await this.completeUpload(uploadId, parts); return result; } catch (error) { console.error('アップロード失敗', error); throw error; } } async uploadParts(presignedUrls) { const queue = Object.entries(presignedUrls); const parts = []; let retryCount = 0; // リトライ回数の記録 const uploadPart = async () => { while (queue.length > 0) { const [partNumber, url] = queue.shift(); const start = (partNumber - 1) * this.chunkSize; const end = Math.min(partNumber * this.chunkSize, this.file.size); const chunk = this.file.slice(start, end); try { const response = await fetch(url, { method: 'PUT', headers: { 'Content-Type': 'application/octet-stream' }, body: chunk }); if (!response.ok) { throw new Error(`パート ${partNumber} のアップロード失敗`); } const eTag = response.headers.get('ETag'); parts.push({ PartNumber: parseInt(partNumber), ETag: eTag }); } catch (error) { // シンプルなリトライ機構 if (retryCount < 3) { retryCount++; queue.unshift([partNumber, url]); // キューの先頭に戻す await new Promise(resolve => setTimeout(resolve, 1000 * retryCount)); } else { throw error; } } } }; // 指定された並列数でアップロード実行 await Promise.all( [...Array(this.maxConcurrency)].map(() => uploadPart()) ); return parts.sort((a, b) => a.PartNumber - b.PartNumber); } // 他のメソッドは省略... }
実装中にハマったのが、並列数の調整でした。最初は10並列とかでやってたんですが、クライアントPCの負荷が高くなりすぎて、逆に遅くなったり、ブラウザが固まったりしました。
転んで覚えるタイプなので、色々試した結果、5並列が一番バランス良かったです。
バックエンド実装(署名付きURL生成)
バックエンド側では、署名付きURLの一括生成を効率的に行う実装を追加しました。Laravel愛用者の僕としては、このあたりはお馴染みの実装ですね。
<?php class MultipartUploadService { public function generatePresignedUrls( string $uploadId, string $fileName, int $totalParts ): array { $s3Client = Storage::disk('s3')->getAdapter()->getClient(); $bucket = config('filesystems.disks.s3.bucket'); $urls = []; for ($partNumber = 1; $partNumber <= $totalParts; $partNumber++) { $command = $s3Client->getCommand('UploadPart', [ 'Bucket' => $bucket, 'Key' => $fileName, 'UploadId' => $uploadId, 'PartNumber' => $partNumber, ]); $request = $s3Client->createPresignedRequest($command, '+20 minutes'); $urls[$partNumber] = (string) $request->getUri(); } return $urls; } }
リスク軽減策
コア機能であり不具合発生時の影響も大きくなることが想定されるため、慎重なリリース手順を踏みました。
即座の切り戻し機能として、関数切り替えのみで旧機能に復帰可能にしておき、既存アップロード機構を改修後1ヶ月間維持しました。
段階的有効化では、確実にアップロード機能を使ってるが不具合時に影響が少ない特定ユーザーグループから順次適用し、問題なければ改修から1ヶ月後に全ユーザ適用としました。
ユーザー体験の向上
技術的改善だけでなく、UX面でも改善を実現しました。
指数バックオフ方式のリトライ機構を導入しました。従来なかった自動リトライ機能を導入し、通信断絶時も自動復旧するようになり、手動でのアップロードやり直しが不要になりました。
アップロード機能のUX改善も行いました。もともと使っていたチャンクアップロードを使わなくなった結果、こちらの改修も必要になりました。ファイル添付の挙動をW3C標準に合わせ、ファイル添付やアップロード時の進捗バーなどが視覚的にわかりやすくなるよう改善しました。
学んだこと
技術面での学び
マルチパートアップロードの深い理解を通じて、AWSのサービスをただ使うだけでなく、その特性を深く理解することの重要性を実感しました。並列数の調整やチャンクサイズの最適化など、細かなパラメータ調整が最終的なパフォーマンスに大きく影響することがよくわかりました。
最初は「マルチパートアップロードを使えば自動的に速くなる」程度の理解でしたが、実際には多くの調整が必要でした。実際に手を動かしてみないと分からないことばかりでしたね。
DDD設計の実践的価値
DDD設計についても、理論だけでなく実践的な価値を体感できました。特に腐敗防止層という概念が、単なる設計の美しさではなく、実際の開発効率やリスク軽減に直結することを学びました。
7年運営で技術負債が蓄積したプロダクトにおいて、DDD設計は「安全な変更」を可能にする強力な武器となることを実感しました。もうDDD無しの開発は考えられません。
プロジェクト管理面での学び
事前検証の重要性を改めて感じました。実装前に十分な時間をかけて検証したことで、開発中に方針転換することなく、予定通りにリリースできました。
また、技術的に正しい解決策を見つけることと、それを安全に本番環境に適用することは全く別のスキルだということも実感しました。今回の移行戦略は、技術力以上に慎重な計画立案と段階的なアプローチが成功の鍵だったと思います。
おわりに
今回のアップロード機能改修を通じて、パフォーマンス改善だけでなく、システム設計やプロジェクト管理について多くのことを学べました。
特に意識した点は、技術選択から実装→移行まで一貫して「ユーザー体験の向上」と「システムの安定性」の両立を追求することでした。技術者としての理想的な仕事ができて最高でした。
マルチパートアップロードという技術的な解決策と、腐敗防止層による安全な設計、そして慎重な移行戦略。これらが組み合わさることで、単なる機能改善を超えた価値を生み出せたのではないかと思います。
今後も、こういった技術改善を通じて、より良いプロダクトづくりに貢献していきたいと考えています。まだまだ修行中ですが、引き続き実験していきます!
そういえば、まだ改善の余地はいくつかあります。リトライ回数の最適化やエラーハンドリングの更なる改善など、継続的に取り組んでいきたい課題もあります。インフラ周りはまだ修行中なので、詳しい方いたら教えてほしいです。
同じような経験をした方いらっしゃいますか?皆さんも似たような課題に直面されてる場合は、ぜひ参考にしていただければと思います。何か質問があれば、気軽にコメントやX(旧Twitter)でお声がけください。アドバイスももらえると嬉しいです!