この記事はウィルゲート Advent Calendar 2025 1日目の記事です。
はじめに
こんにちは!ウィルゲート開発グループの中尾(@NobleNomad41)です!
Claude Code + .mdファイル + GitHub Issues。
弊チームのAI駆動開発は、この3つで回っています。Claude SkillsもSubagentも使っていません。流行りのAIツールを色々導入して...みたいな話ではなく、かなりシンプルな構成です。
正直なところ、Skills等を導入していないのは「これから調査や仮導入を行うフェーズだから」というのが実情です。ただ、結果論としてこの構成には意外なメリットがありました。Claude Codeに依存しない、他のAIエージェントでも転用可能な運用になっているという点です。
今回は、この運用を実際にやってみて分かったメリット・デメリットを、具体的なファイル構成やエピソードと共に紹介します。同じような課題を抱えている方の参考になれば幸いです。
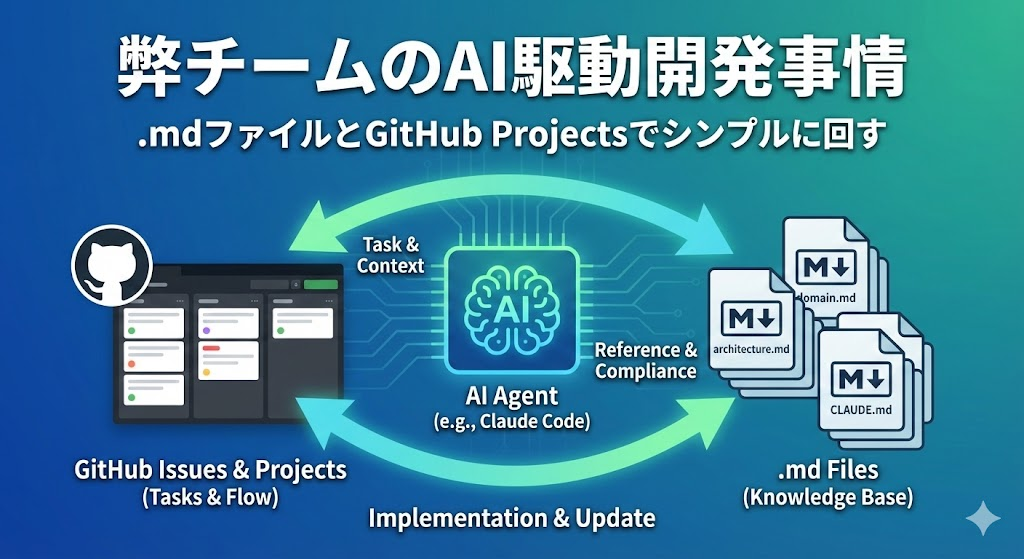
全体像
使用しているもの
- Claude Code: メインの開発エージェント
- GitHub Issues: タスク管理・要件定義
- .mdファイル群: 設計指針・ドメイン知識・ルールの蓄積
使用していないもの
- Claude Skills
- Subagent
- Cursor等の他AIエディタ
繰り返しになりますが、使っていない理由は「調査がまだでこれから行っていく」というのが正直なところです。ただ、この制約が逆に「AI固有機能に依存しない」という設計方針につながりました。
ファイル構成の概要
project/
├── CLAUDE.md # 100行程度
├── docs/
│ ├── architecture.md # 設計指針・レイヤー定義
│ ├── commit-rules.md # コミット規約
│ └── domain/
│ └── [集約名].md # 集約ルートごとのドメイン知識
└── .github/
└── ISSUE_TEMPLATE/
└── feature_request.yml
ポイントは、CLAUDE.mdに全てを詰め込まず、役割ごとにドキュメントを分散させていることです。詳細は後述します。
各ドキュメントの役割と設計意図
CLAUDE.md - 「道しるべ」に徹する
弊チームのCLAUDE.mdは100行程度。中身はほぼ空っぽです。
「え、それで大丈夫なの?」と思われるかもしれませんが、今のところはこれで十分回っています。CLAUDE.mdの役割を「全てを詰め込む場所」ではなく「参照先への道しるべ」に限定したことで、メンテナンスコストを最小限に抑えられています。
# CLAUDE.md(イメージ) ## プロジェクト概要 本プロダクトは〇〇管理システム。 DDD + クリーンアーキテクチャを採用。 ## 設計指針の参照 **MUST: コード改修時は `docs/architecture.md` を必ず参照** ## コミットルール `docs/commit-rules.md` を参照 ## 主要なビジネスドメイン - ユーザー管理 - 案件管理 - 作業フロー管理 ...
なぜこの形にしたか。理由は3つあります。
肥大化防止。全部書くとメンテナンスが破綻します。プロダクトの規模が大きくなるほど1ファイルに集約する運用は現実的ではなくなりますし、必要以上にコンテキストを使用してしまいます。
人間との共用。各ドキュメントは開発者も参照します。AI専用のファイルを別途管理するよりも、人間が普段から使っているドキュメントをAIにも読ませる方が、二重管理を避けられます。
AIの自走性。「どこを見ればいいか」さえ分かればAIは自分で読みに行けます。毎回全てのドキュメントを読み込ませる必要はなく、必要に応じて参照させる形で十分です。
architecture.md - 設計の「憲法」
レイヤー構造、コンポーネントの責務、実装判断基準を定義しています。
弊プロダクトは7年間運用している中で人の入れ替わりが激しく、設計思想がばらばらになっていました。Value ObjectやEntityを使う基準が不明確だったり、UseCasesやInterfaceを使う理由が曖昧だったり。明確な基準がないまま慣習に従って開発を続けた結果、人によって設計が異なる状態になっていました。
この状況でAIに「良い感じに書いて」と頼んでも、当然ながら「良い感じ」の基準がAIには分かりません。
そこで、architecture.mdに以下のような内容を明文化しました。
# アーキテクチャ設計書(抜粋) ## 基本思想 - DDD(ドメイン駆動設計) - クリーンアーキテクチャ ## 4層構造 1. Presentation層(受け渡し・提示) 2. Application層(振る舞い) 3. Domain層(業務知識) 4. Infrastructure層(技術関心) ## 依存関係 Presentation → Application → Domain ← Infrastructure すべての層は最終的にDomain層に依存し、 Infrastructure層もDomain層に定義されたInterfaceを実装する形で 依存関係を逆転させる。
特に効果があったのは判断基準の明文化です。
「Entity/Value Objectの使い分けは?」「Domain Serviceを使う基準は?」といった設計判断をフローチャート形式で明示しています。
## Entity vs Value Object 判定基準 対象となるデータ/概念を以下のフローで判定する: 1. 一意性が必要? - NO → Value Object - YES → 次へ 2. ライフサイクルがある? - NO → Value Object - YES → 次へ 3. 他のオブジェクトから参照される? - NO → Value Object - YES → Entity
このフローチャートがあることで、AIは「この概念はEntityにすべきかValue Objectにすべきか」を自分で判定できるようになりました。
実際に、architecture.mdを整備する前と後で、AIの出力品質は明らかに変わりました。
整備前は、Controllerにビジネスロジックがベタ書きされたコードが出てくるなど品質に問題がありました。「まあ動くけど...」という品質です。依頼するたびに「レイヤー分離して」「Value Object使って」と繰り返し指示する必要がありました。
整備後は、UseCaseへの委譲、Domain層へのロジック集約が自然と行われるようになりました。判断基準をフローチャートで明示したことで、AIが「この処理はどの層に置くべきか」を自分で判定できるようになっています。毎回同じ指示を繰り返す必要がなくなり、開発効率が明らかに上がりました。
commit-rules.md - 品質の最低ラインを担保
コミットメッセージの規約だけでなく、改修完了の定義も含めています。
## 改修完了時のルール - make cs(コーディング規約チェック) - make phpstan(静的解析) - make test(テスト実行) → 壊れたテストがある状態で改修完了としない ## コミットメッセージの構造 <type>: <subject> ## Type(必須) - feat: 新機能の追加 - fix: バグ修正 - refactor: リファクタリング - docs: ドキュメントの変更 - test: テストの追加・修正 - chore: ビルドプロセスやツールの変更 ## Subject(必須) - 50文字以内で変更内容を簡潔に記述 - 命令形で記述(例:「〜を追加」「〜を修正」)
AIが「完了しました」と言っても、これらのチェックを通すことが必須になっています。
地味ですが、これがあることで「AIに任せたら壊れたコードがコミットされていた」という事故を防げています。コミットの粒度・形式も自然と統一されるようになりました。
domain.md - 集約ルートごとのドメイン知識
ここが一番効果を実感しているポイントです。
プロダクト固有の用語、ビジネスルール、状態遷移を定義しています。重要なのは、集約ルートごとに分けて管理していること。
# [集約名] ドメイン知識 ## 概要 解決する課題: ○○の管理と進捗把握 対象ユーザー: 運営担当者、外部パートナー ## ユビキタス言語 | ドメイン用語 | クラス名 | 説明 | |------------|---------|------| | 案件 | Project | 作業の単位 | | 工程 | Process | 案件内の作業ステップ | ## ビジネスルール ### 不変条件 - 承認後のキャンセルは不可 - 1つの工程に複数担当者のアサインは不可 ### 状態遷移 募集中 → 応募済 → 承認 → 作業中 → 完了 ## Claude Code向け指示 優先事項: - 状態遷移の整合性チェック - 不変条件の担保 既存の問題: - 一部で直接DB更新あり(要リファクタ)
「ドメイン知識を1ファイルにまとめよう」とすると1ファイルに全部書くと肥大化して破綻することが懸念されるため集約ルートごとに分けています。
結果論ではありますが、予想外の効果がありました。
「この集約は何に依存しているか」を意識せざるを得なくなったのです。
domain.mdを書くときに、「この集約のドキュメントに、別の集約の話を書いていいのか?」と考えるようになります。書いてしまうと、そのドキュメントは複数の集約に依存することになり、メンテナンスが複雑になります。
結果として、ドキュメント設計が疎結合なら、コード設計も疎結合になるという副次効果が生まれました。
これは狙っていなかった効果でした。AIのためにドキュメント整備していたら、人間側の設計思考も整理されていたという嬉しい誤算です。
逆に、domain.mdを用意せずにAIに実装させたケースでは、かなり混乱した出力になりました。
プロダクト固有の用語の使われ方が一般的な意味とずれていたり、ビジネスルールを無視した実装になっていたり。特に、集約の境界が曖昧なまま実装させると、本来分離すべきエンティティ同士が密結合になるケースがありました。
domain.mdを整備してからは、こうした問題は大幅に減っています。AIにとっても「このコンテキストで〇〇はこういう意味」という前提が明確になることで、適切な実装ができるようになったのだと思います。
GitHub Issue駆動の運用
IssueテンプレートをYAMLで定義する
弊チームでは、GitHub IssuesのテンプレートをYAMLで厳密に定義しています。
狙いは2つ。
- 人間に必要情報を漏れなく書かせる
- AIが構造的に理解しやすい形式にする
# .github/ISSUE_TEMPLATE/feature_request.yml(抜粋) name: 新機能リクエスト 🚀 description: 新しい機能の追加を提案する body: - type: textarea id: summary attributes: label: 機能概要 description: 追加したい機能について簡潔に説明してください validations: required: true - type: textarea id: background attributes: label: 背景・動機 description: なぜこの機能が必要なのか説明してください validations: required: true - type: dropdown id: related_domain attributes: label: 関連ドメイン description: どのビジネスドメインに関連しますか? options: - ユーザー管理 - 作業フロー管理 - 支払い管理 - その他 validations: required: true - type: checkboxes id: architecture_layer attributes: label: 影響範囲(アーキテクチャ層) description: どの層に影響がありますか? options: - label: Presentation層 - label: Application層 - label: Domain層 - label: Infrastructure層 - type: textarea id: acceptance_criteria attributes: label: 受け入れ基準 description: この機能が完成したと判断する基準 validations: required: true
ドロップダウンやチェックボックスを使うことで、曖昧な記述を防ぎつつ、AIが「このIssueはDomain層に影響がある」と即座に判断できるようになっています。
自由記述だけだと、人によって書き方がバラバラになり、AIが解釈に迷うケースがありました。選択式の項目を入れることで、構造化された情報をAIに渡せるようになっています。
運用パターン
現在、大きく2つのパターンで運用しています。
パターンA: 明確な要望がある場合
1. 要望をIssueに起票(テンプレートに沿って) 2. AIに「このIssueを解決して」と依頼 3. AIが実装
要件が固まっている場合はこちら。Issueテンプレートで必要情報が揃っているので、AIへの追加説明がほぼ不要になります。
「関連ドメイン」「影響範囲」が明示されているので、AIは該当するdomain.mdやarchitecture.mdの該当セクションを参照して実装を進められます。
パターンB: 曖昧な段階の場合
1. AIに調査・設計を依頼 2. 結果をIssueに残す 3. 後でやる/やらないを判断、要件を固める 4. 固まったらパターンAへ
「なんかこの辺改善したいけど...」みたいな曖昧な段階ではこちら。AIに調査させた結果をIssueとして残しておくことで、フロー情報のドキュメントとして活用できます。
後から見返したときに「なぜこの判断をしたか」「どんな選択肢を検討したか」が追えるのは地味に便利です。
やってみて分かったこと
メリット
1. ツール非依存で移行しやすい
.mdファイルとGitHub Issuesという汎用的な仕組みだけで運用しているため、Claude Code以外のAIエージェントにも転用可能です。
Claude Skillsのような専用機能を使っていないことで、将来的に別のツールに移行する際のロックインリスクを回避できています。
実際、Github Copilotなど他のAIツールを試す機会があったときも、.mdファイルをそのまま読み込ませるだけで同様の効果が得られました。AI固有の設定ファイルを作り込んでいたら、こうはいかなかったと思います。
2. ガイドライン準拠のコードが安定して出る
architecture.mdやdomain.mdを整備したことで、毎回同じ指示をしなくても、プロダクトのガイドラインに則したコードが返ってくるようになりました。
「レイヤー分離して」「Value Object使って」「この用語はこういう意味だから」といった指示を繰り返す必要がなくなり、開発効率が上がっています。
特にarchitecture.mdの効果は大きかったです。整備前は「なんとなく動くコード」が出てくることが多かったですが、整備後は設計方針に沿ったコードが安定して出るようになりました。
3. 副次効果:疎結合設計を意識するきっかけに
集約ルートごとにdomain.mdを分けて管理する運用にしたことで、「この集約は他の集約と依存していないか?」を自然と意識するようになりました。
AIのためのドキュメント整備が、結果的に設計品質の向上にもつながっています。
これは本当に予想外でした。「AIに読ませるドキュメントを書く」という作業が、「設計を言語化する」という作業と同義だったのです。言語化する過程で、曖昧だった設計方針が明確になり、チーム内での認識のずれも減りました。
デメリット / 課題
1. ドキュメント整備コストは必要
当然ですが、.mdファイルは人間が書く必要があります。
architecture.mdやdomain.mdはAI駆動開発を始める前には存在しなかったので、導入時にはそれなりの整備コストがかかりました。
ただ、一度整備してしまえばメンテナンスコストは低く抑えられています。大きな設計変更がない限り、architecture.mdを頻繁に更新する必要はありません。domain.mdも、新しい集約が増えたときに追加する程度です。
初期投資は必要ですが、その後のリターンを考えると十分にペイすると感じています。
とはいえ、この辺はSerena等を導入することで自動的にAIが回収しやすいよう整備してくれるなどの話も聞くため、必要に応じて導入・活用していきたいです。
2. コンテキスト消費量が増える
Claude Skillsのような最適化された仕組みと比べると、.mdファイルを毎回読み込む分、コンテキストの消費量は増えます。
大規模なドキュメントを用意しすぎると、コンテキストウィンドウを圧迫するリスクがあります。CLAUDE.mdを「道しるべ」に徹する設計にしているのは、この問題への対策でもあります。
必要なドキュメントだけを参照させる運用にすることで、ある程度は緩和できていますが、Skills等を使った最適化には及ばないと思います。
3. 設計判断は依然として人間が必要
AIが出力するコードは、architecture.mdに沿ったレイヤー分離はできるようになりました。ただ、より高次の設計判断については、まだ人間の確認が必要です。
具体的に困ったのは、Domain Serviceが過剰に膨れ上がる傾向があったことです。
本来Entityに持たせるべきロジックがServiceに行きがち、という問題が発生しました。AIは「複数のオブジェクトにまたがる処理はDomain Service」というルールは守ってくれるのですが、「この処理は本当に複数オブジェクトにまたがっているのか?」という判断が甘いことがありました。
振り返ると、これはdomain.mdで「どこまでが集約か」「このEntityはどんな責務を持つか」を十分に明示できていなかったことが原因だったと思います。domain.mdを充実させることである程度改善しましたが、完全ではありません。
AIが出力したコードを人間がレビューする工程は、今のところ省略できないと考えています。
まとめ
弊チームのAI駆動開発は、Claude Code + .mdファイル + GitHub Issuesというシンプルな構成で運用しています。
Claude SkillsやSubagentといった専用機能は使っていませんが、それでも十分に開発効率は上がっています。むしろ、汎用的な仕組みだけで運用することで、ツールロックインのリスクを回避できているというメリットもあります。
ポイントをまとめると以下の通りです。
- CLAUDE.mdは「道しるべ」に徹し、詳細は各ドキュメントに分散
- architecture.mdで判断基準を明文化し、AIの設計判断を支援
- domain.mdは集約ルートごとに分け、疎結合設計を促進
- IssueテンプレートをYAMLで定義し、AIが構造的に理解しやすい形式に
今後、余裕ができればClaude Skillsの導入も検討したいと考えています。コンテキスト消費量の削減や、より高度な自動化が期待できそうです。
また、現状ではAIの設計判断に人間のレビューが必要な部分が残っています。domain.mdのさらなる充実や、設計レビュー観点のドキュメント化など、まだ改善の余地はありそうです。
同じようにAI駆動開発の運用を模索している方の参考になれば幸いです。
「ウィルゲート Advent Calendar 2025」、翌日はtattaka_sさんの「プラス状態のマインド、マイナス状態のマインドを認識して対処する」です!